发布时间:2022-08-19 12:57
System.out.println("redis每秒操作:" + i + "次");
}
-----------测试结果-----------
redis每秒操作:10734次
[](https://gitee.com/vip204888/java-p7)
---------------------------------------------------------------
2、使用Redis连接池
跟数据库连接池相同,Java Redis也同样提供了类 `redis.clients.jedis.JedisPool`来管理我们的Reids连接池对象,并且我们可以使用 `redis.clients.jedis.JedisPoolConfig`来对连接池进行配置,代码如下:
JedisPoolConfig poolConfig = new JedisPoolConfig();
// 最大空闲数
poolConfig.setMaxIdle(50);
// 最大连接数
poolConfig.setMaxTotal(100);
// 最大等待毫秒数
poolConfig.setMaxWaitMillis(20000);
// 使用配置创建连接池
JedisPool pool = new JedisPool(poolConfig, “localhost”);
// 从连接池中获取单个连接
Jedis jedis = pool.getResource();
// 如果需要密码
//jedis.auth(“password”);
Redis只能支持六种数据结构 (string/hash/list/set/zset/hyperloglog)的操作 ,但在Java中我们通常以类对象为主,所以在Redis存储的数据结构月java对象之间进行转换,如自己编写一些工具类 比如一个角色对象的转换,还是比较容易的,但是涉及到许多对象的时候,这其中无论工作量还是工作难度都是很大的,所以总体来说, 就操作对象而言,使用Redis还是挺难的,好在spring对这些进行了封装和支持。
八、Redis在Java Web中的应用
--------------------
Redis 在 Java Web 主要有两个应用场景:
* 存储缓存用的数据
* 需要高速读写的场合
### [](https://gitee.com/vip204888/java-p7)1、存储缓存用的数据
在日常对数据库的访问中,读操作的次数远超写操作,比例大概在 1:9 到 3:7,所以需要读的可能性是比写的可能大得多的。当我们使用SQL语句去数据库进行读写操作时,数据库就会去磁盘把对应的数据索引取回来,这是一个相对较慢的过程。
如果放在Redis中,也就是放在内存中,让服务器直接读取内存中的数据,那么速度就会快很多,并且会极大减少数据库的压力,但是使用内存进行数据存储开销也是比较大的,限于成本的原因,一般我们只是使用Redis存储一些常用的和主要的数据,比如用户登录信息等。
一般而言在使用 Redis 进行存储的时候,我们需要从以下几个方面来考虑:
[](https://gitee.com/vip204888/java-p7)(1)业务数据常用吗?使用率如何?
如果使用率较低,就没必要写入缓存。
[](https://gitee.com/vip204888/java-p7)(2)该业务是读操作多,还是写操作多?
如果写操作多,频繁需要写入数据库,也没必要使用缓存。
[](https://gitee.com/vip204888/java-p7)(3)业务数据大小如何?
如果要存储几百兆字节的文件,会给缓存带来很大的压力,这样也没必要。
在考虑了这些问题之后,如果觉得有必要使用缓存,那么就使用它!使用 Redis 作为缓存的读取逻辑如下图所示:
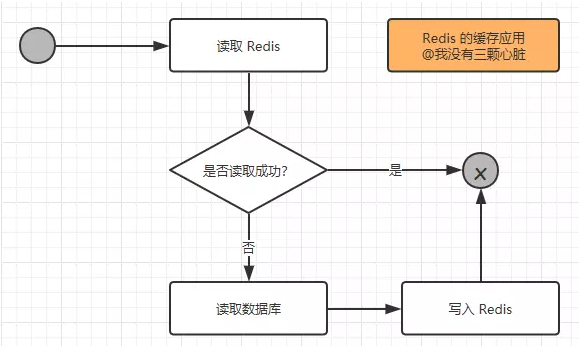
从上图我们可以知道以下两点:
(1)当第一次读取数据的时候,读取Redis的数据就会失败,此时就会触发程序读取数据库,把数据读取出来,并且写入Redis中
(2)当第二次以及以后需要读取数据时,就会直接读取Redis,读取数据后就结束了流程,这样速度大大提高了。
从上面的分析可以知道,读操作的可能性是远大于写操作的,所以使用 Redis 来处理日常中需要经常读取的数据,速度提升是显而易见的,同时也降低了对数据库的依赖,使得数据库的压力大大减少。
分析了读操作的逻辑,下面我们来看看写操作流程:
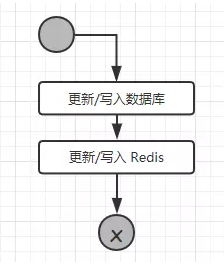
从流程可以看出,更新或者写入的操作,需要多个 Redis 的操作,如果业务数据写次数远大于读次数那么就没有必要使用 Redis。
### [](https://gitee.com/vip204888/java-p7)2、高速读写场合
在如今的互联网中,越来越多的存在高并发的情况,比如天猫双11、抢红包、抢演唱会门票等,这些场合都是在某一个瞬间或者是某一个短暂的时刻有成千上万的请求到达服务器,如果单纯的使用数据库来进行处理,就算不崩,也会很慢的,轻则造成用户体验极差用户量流水,重则数据库瘫痪,服务宕机,而这样的场合都是不允许的!
所以我们需要使用 Redis 来应对这样的高并发需求的场合,我们先来看看一次请求操作的流程:
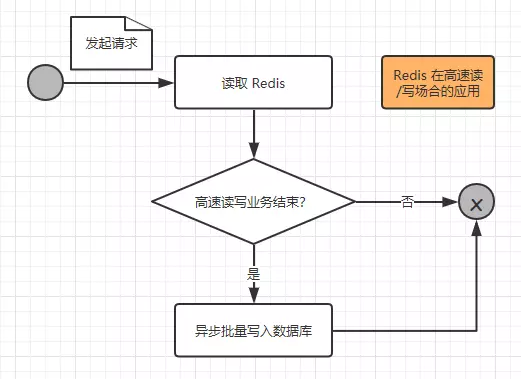
我们来进一步阐述这个过程:
(1)当一个请求到达服务器时,只是把业务数据在Redis上进行读写,而没有对数据库进行任何的操作,这样就能大大提高读写的速度,从而满足高速相应的需求。
(2)但是这些缓存的数据仍然需要持久化,也就是存入数据库之中,所以在一个请求操作完Redis的读写之后,会去判断该高速读写的业务是否结束,这个判断通常会在秒杀商品为0,红包金额为0时成立,如果不成立,则不会操作数据库;如果成立,则触发事件将Redis的缓存的数据以批量的形式一次性写入数据库,从而完成持久化的工作。
九、在spring中使用Redis
-----------------
上面说到了 Redis 无法操作对象的问题,无法在那些基础类型和 Java 对象之间方便的转换,但是在 Spring 中,这些问题都可以通过使用RedisTemplate得到解决!
想要达到这样的效果,除了 Jedis 包以外还需要在 Spring 引入 spring-data-redis 包。
### [](https://gitee.com/vip204888/java-p7)1、使用spring配置JedisPoolConfig对象
大部分的情况下,我们还是会用到连接池的,于是先用 Spring 配置一个 JedisPoolConfig 对象:
### 2、为连接池配置工厂模型
好了,我们现在配置好了连接池的相关属性,那么具体使用哪种工厂实现呢?在Spring Data Redis中有四种可供我们选择的工厂模型,它们分别是:
* JredisConnectionFactory
* JedisConnectionFactory
* LettuceConnectionFactory
* SrpConnectionFactory
我们这里就简单配置成JedisConnectionFactory:
### 3、配置RedisTemplate
普通的连接根本没有办法直接将对象直接存入 Redis 内存中,我们需要替代的方案:将对象序列化(可以简单的理解为继承Serializable接口)。我们可以把对象序列化之后存入Redis缓存中,然后在取出的时候又通过转换器,将序列化之后的对象反序列化回对象,这样就完成了我们的要求:
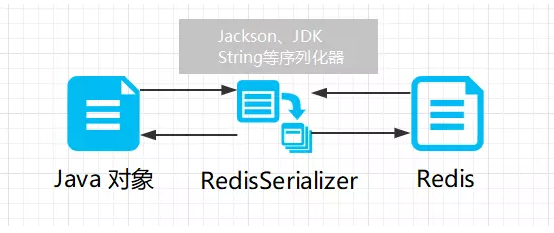
RedisTemplate可以帮助我们完成这份工作,它会找到对应的序列化器去转换Redis的键值:
/** @author: 素小暖 @create: 2020-2-12 class="org.springframework.data.redis.core.RedisTemplate"
p:connection-factory-ref="connectionFactory"/>
### 4、测试
首先编写好支持我们测试的POJO类:
深度学习环境准备之docker常用操作详解和pycharm/tensorboard远程使用方法
【0基础运筹学】【超详细】列生成(Column Generation)
Python使用BeautifulSoup4修改网页内容的实战记录
技术解析|Doris Connector 结合 Flink CDC 实现 MySQL 分库分表 Exactly Once精准接入
C++输入3个字符串,按由小到大的顺序输出(用指针方法处理),VS2017strcpy使用与strcpy_s使用
fastai v1环境搭建:Win10 MX250 CUDA10.1 cuDNN Pytorch1.0.0 Fastai v1安(bi)装(keng)指南
《算法图解》读书笔记-2 第一章 算法简介 二分查找算法(python实现代码)时间复杂度 旅行商问题